| Добавить Архитектура Запросы сейчас Цифры и факты FAQ Кнопка поиска Сделать стартовой |
Поисковая система "Turtle".
Физиология и анатомия.Д.В.Крюков, Stack Technologies Ltd. dvk@stack.net
Краткий обзор (abstract).
В данной работе мы представляем "Turtle" как прототип распределенной, крупной и масштабируемой поисковой системы по интернет-ресурсам гипертекстовых документов. Эта система позволяет с большой эффективностью производить индексирование и поиск по огромным коллекциям документов. Полнотекстовая поисковая система ориентирована на документы, составленные на разных языках. Рабочий вариант поисковой машины представлен на /. В качестве прототипа поисковая система может рассматриваться как стартовая точка для разработки истинно распределенной по множеству участников сети поисковой системы. Конечно, это требует дополнительных исследований.Ключевые слова.
World Wide Web, Search Engines, поисковые машины, индексирование документов, Turtle.1. Введение.
Оглядываясь на предшествующие разработки (в том числе и свои собственные) в области поисковых систем, ориентированных на Web в нашей стране и за рубежом, оценивая их сильные и слабые стороны, учитывая разнообразные (по сложности запросов) потребности сетевого сообщества и множество других факторов, мы задумали спроектировать систему, наиболее полно удовлетворяющую эти потребности. Кроме исследовательского интереса к решению проблем, мы также хотели показать сетевому сообществу потенциальные возможности нашей команды разработчиков в построении систем любой сложности. На вопрос "Зачем нужен новый поисковик? Почему вы его делаете?" я отвечаю обычно: "Потому, что он другой".В своей работе "The Anatomy of a Large-Scale Hypertextual Web Search Engine" Sergey Brin и Lawrence Page раскрыли некоторые аспекты анатомии прототипа поисковой системы Google. Мы также решили не скрывать "внутренностей" прототипа нашей поисковой машины "Turtle" и, кроме "анатомических" данных, приводим здесь описание некоторых "физиологических" аспектов функционирования "Turtle", которые в той или иной степени характеризуют современные Web-поисковики.
Какие основные задачи мы хотим решить в данной разработке?
Во-первых, построение поисковой системы, способной работать с предельно большими объемами информации. Мы не стали ограничиваться уровнем страны или региона. Мы проектировали систему мирового масштаба, способную составить конкуренцию признанным мировым лидерам - таким, как Google, AltaVista и другим. В текущей конфигурации мы ограничили поле деятельности поисковой системы пределами России, включая страны Содружества, однако сама система имеет практически не ограниченную масштабируемость.
Во-вторых, мы желали построить истинно многоязыковую поисковую систему, способную определять исходные языки документов, оперировать с морфологическими формами различных языков в запросах и ответах. Сейчас система умеет оперировать данными 24 языков, включая некоторые экзотические (например, эсперанто или русская транслитерация, см. Multilingual Morphology Module MMM/1.0).
В-третьих, мы желали дать в руки рядовых владельцев сайтов инструмент, с помощью которого можно изготовить свою локальную поисковую систему. Идея заключается в том, что при создании локальной поисковой базы обновление данных синхронно производится как в самой локальной базе, так и в центральной базе поисковой системы "Turtle". Таким образом, актуальность данных в поисковой системе полностью зависит от того, с какой частотой может себе позволить конкретный владелец ресурса или группы ресурсов сканировать эти ресурсы на предмет обновления индекса. Такие обновления в центральной базе будут осуществляться в реальном времени с частотой сканирования ресурса. Если владельцу ресурса не требуется локальная поисковая система, то он может использовать наше программное обеспечение исключительно для обновления информации о состоянии его ресурсов в нашей базе.
Развивая дальше эту идею, мы приходим к выводу, что такой механизм легко позволяет создать региональные, областные, республиканские базы и т.д. Коллекции могут создаваться не только по территориальному принципу, но и по тематическому. При этом центральная база в любой момент имеет знания о принадлежности какого-либо документа к конкретным коллекциям. Это свойство может быть легко использовано в дальнейшем для ограничения тематики поиска.
В-четвертых, учитывая распределенных характер хранения информации в сети, мы пришли к выводу, что и характер обработки этой информации должен иметь распределенную сетевую структуру, и применили этот принцип во всех компонентах поисковой системы "Turtle". Так, например, сканирование производится множеством агентов под руководством центрального диспетчера, индекс для поиска распределен по другим серверам, причем это не является копированием полного индекса на разные сервера. В процессе обработки одного поискового запроса в работу могут быть задействованы десятки серверов различной направленности действия. На многих этапах обработки поискового запроса возможна параллельная работа серверов, этим достигается снижение результирующего времени обработки запроса. Вся работа, производимая в рамках поисковой системы, в основе своей содержит сетевые взаимодействия различных компонент в различных узлах сети системы. Для их успешного взаимодействия в рамках проекта разработан специальный протокол Search System Transfer Protocol (SSTP.1.0). Данные от внешних накопителей данных, установленных в других компаниях для создания собственных поисковых систем, также передаются посредством этого протокола компонентам центральной поисковой системы в компактном компрессированном виде.
В-пятых, мы старались сделать результаты разработки максимально открытыми для вовлечения в процесс совершенствования системы большого количества внешних специалистов. В этом документе мы раскроем основополагающие принципы работы данной поисковой системы. Мы собираемся распространять исходные тексты той части, которая позволяет пользователям строить свои локальные базы, когда этот этап работы будет близок к завершению.
В-шестых, понимая, что количество информации в сети растет со значительным опережением возможностей отдельно взятой компании, как бы велика она ни была, мы надеемся, что данная разработка может являться началом разработки истинно распределенного механизма поиска в сети, в процессе которого смогут принимать участие вычислительные ресурсы многих компаний и организаций.
В-седьмых, в рамках построения поисковой системы мы поставили задачу создания ретроспективной базы данных состояния ресурсов сети в отдельно взятый интервал времени. Это означает, что на практике можно будет увидеть, как выглядел тот или иной ресурс три месяца или год назад. Данная часть проекта могла бы стать, по нашему мнению, частью национальной программы создания библиотеки ресурсов. Бережно сохраненные данные могут использоваться новыми поколениями для своих анализов.
В-восьмых, мы ориентируемся на множество форматов данных документов. Классические поисковые системы чаще всего "умеют" работать только с текстовыми документами. Мы построили систему легкого подключения неограниченного числа фильтров-преобразователей форматов. Например, сейчас "Turtle" умеет индексировать документы форматов Microsoft Word, Excel, RTF, PDF, PostScript, PowerPoint и др. Система легко оперирует компрессированными данными различных форматов. Подключение любого нового преобразователя - не проблема.
В-девятых, мы поставили перед собой задачу создания нового механизма ранжирования результатов поиска, учитывающего в себе все известные на сегодня и включающего разработанные нами оригинальные методы.
Отдельные материалы данной разработки могут использоваться для обучения проектированию различных составляющих поисковой системы. Так, например, при проектировании поиска по распределенной базе данных, находящейся на многих Процессорах Поиска (Search Processors), был разработан специальный программный язык Search System Assembly Language (SSAL). Программы, написанные и оптимизированные на нем внешними приложениями, выполняются на SP, позволяя оптимально взаимодействовать различным компьютерам при выполнении операций поиска.
Большое внимание было уделено безопасности работы поискового комплекса, в результате чего в рамках разработанного сетевого протокола реализована многоуровневая система авторизации и идентификации объектов сетевого взаимодействия.
Все эти, а также другие особенности поисковой системы "Turtle" с различной степенью детализации будут рассмотрены в данной работе.
2. Текущая реализация прототипа.
Как отмечалось во введении, программное обеспечение разрабатывалось таким образом, чтобы быть способным вместить в себя практически не ограниченное количество информации для поиска. Однако сдерживающим фактором всегда являлся и является экономический фактор. В данной работе мы умышленно конфигурационно ограничили нашу систему рамками сегментов российской (вернее русскоговорящей) сети Интернет. На практике это означает, что центральный узел поисковой системы "Turtle" в текущей реализации для обработки ресурсов таких сегментов сети имеет в своем составе:Многие сервера совмещают со своей основной работой другие вспомогательные функции, требуемые для функционирования всего комплекса. Любая отдельно взятая подсистема с точки зрения функциональности может быть распределена по нескольким физическим серверам без изменения программного обеспечения.
- компьютер центрального диспетчера;
- 10 компьютеров - накопителей данных;
- компьютер коллектора индексов;
- 4 компьютера поисковых процессоров;
- 3 компьютера архивных серверов;
- компьютер формирования и оптимизации поисковых запросов;
- балансировщик нагрузок и кэш-сервер.
Данные российского сегмента мы оценивали примерно так:
Как видно из приведенных цифр, мы старались минимизировать потребность в аппаратных ресурсах за счет высокого качества программных разработок. Удалось нам это или нет - жизнь покажет.
- суммарная совокупность серверов - 500 тыс.
- суммарное количество документов, пригодных для сканирования - 70 млн.
3. Структура и функции.
Если сеть гипертекстовых документов справедливо называют "мировой паутиной", то работу элементов поисковой системы скорее можно сравнить с большим муравейником, где все куда-то спешат, сталкиваются, взаимодействуют. При этом, наблюдая со стороны, трудно понять общую логику. Однако, несомненно, она присутствует и не так сложна, как это может показаться на первый взгляд.Я умышленно не привожу сразу структурную схему реализованной поисковой системы, чтобы в процессе рассуждений наблюдать, как она изменяется в зависимости от промежуточных результатов анализов.
Не надо быть специалистом в области поиска, чтобы определить 3 важнейшие функции жизнедеятельности поискового движка Web-документов. Ими являются:
Существует масса других функций, о которых будет в дальнейшем рассказано, однако их назначение заключается главным образом именно в эффективной поддержке этих трех базовых.
- Извлечение и накопление данных документов.
- Обработка этих данных и создание данных, пригодных для поиска.
- Поиск по созданным данным.
3.1. Базовая функция извлечения данных.
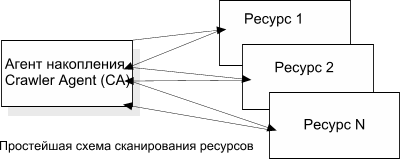
Представим себе, что в нашей системе есть только один компьютер, который занимается сканированием Web-ресурсов, последовательно осуществляя следующие действия:
- Выяснение соответствия логического имени сервера ресурса и его реального Интернет IP-адреса посредством системы Domain Name System (DNS).
- Установление соединения с удаленным сервером.
- Передача запроса серверу посредством Hypertext Transfer Protocol (HTTP).
- Получение от внешнего сервера результатов запроса.
- Анализ ответа и извлечение новых объектов для сканирования (URL).
Предположим, что средняя скорость среды при взаимодействии с внешним сервером составляет примерно 50 КБ/сек (что можно считать весьма реальной ситуацией, т.к. множество ресурсов до сих пор так и не обладает достаточно скоростными каналами подключения). Предположим, что средний размер документа сети составляет 25 КБ, что также близко к реальности. Попытаемся оценить производительность нашей примитивной системы накопления, исходя из таблицы средних времен указанных операций:
DNS 0.05 Соединение с сервером 0.05 Передача запроса 0.05 Прием запроса 0.5 Анализ 0.05 Итого: 0.7 Таким образом, наша система тратит на один документ в среднем 0.7 секунды. Это означает, что за сутки она сможет "обработать" примерно 120 тысяч документов. Вспомним, что российский Интернет по численности документов мы оценивали примерно в 70 млн. Итак, сканирование только российской части Интернета нашей гипотетической системой составит полтора года. Результат не удовлетворителен с любой точки зрения.
Попробуем понять, что можно улучшить в нашей системе. Как видно из таблицы, большую часть времени система простаивает (с точки зрения процессора), она занята приемом данных документа на 70%. Очевидно, что если в любой момент времени систему накопления обеспечить данными для обработки, то работа ее станет куда эффективней. Для того, чтобы данные всегда присутствовали для обработки на накопителе (мы называем его Crawler Agent), достаточно организовать передачу и прием запросов в несколько потоков одновременно, при окончании данных в одном из потоков программа немедленно приступает к обработке данных, полученных из него.
При внедрении подобного метода производительность одного Crawler Agent (CA) может составить примерно 500 тыс. документов в сутки при условии, что мы не модернизировали компьютер CA, в конфигурацию которого входит 64MB RAM, 600Mhz Intel Pentium процессор и недорогой IDE HDD. Время сканирования российского Интернета в таком случае составит уже 140 дней, что существенно лучше, но продолжает быть не удовлетворительным для выполнения поставленной задачи. Пока мы только пришли к выводу, что CA по своей природе должен быть многопоточным.
Теперь попробуем увеличить количество CA с одного до десяти. Время сканирования российской части Интернета составит в этом случае 14 дней, что вполне удовлетворительно для инерционных поисковых систем.
Однако что делать в случае, когда какой-либо документ по каким-либо причинам не содержит ссылок на новые объекты сканирования? Куда помещать результаты сканирования? Как узнать, какую работу уже проделал соседний CA, чтобы избежать повторений? Как уменьшить накладные расходы работы с DNS? Как идентифицировать объект сканирования? Как узнать, изменился ли этот объект с момента последнего сканирования? Возникает масса вопросов.
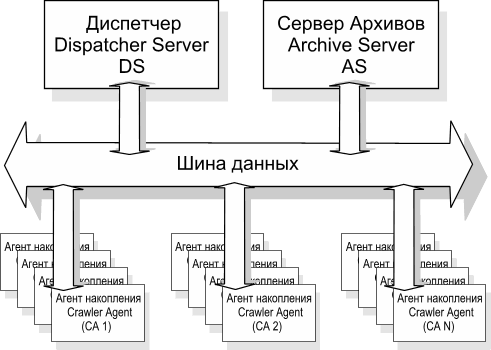
Мы приходим к выводу, что работа множества CA требует координации. Таким координирующим центром может и должен являться центральный диспетчер (Dispatcher Server), который сам непосредственно не занимается сканированием документов, а поддерживает очереди для CA и по их первому требованию может выдать описание нового объекта для сканирования. Диспетчер также занимается отслеживанием результатов сканирования, передаваемых ему агентами, помещением вновь найденных объектов для сканирования в соответствующие очереди с присвоением им уникальных идентификаторов. Он помечает несуществующие документы с целью предотвращения повторного сканирования, может формировать приоритеты в очереди документов и пр.
Рассматривая далее процесс жизнедеятельности CA, законно предположить, что он существует не только для того, чтобы сканировать документы и передавать вновь появившиеся ссылки. С полученными по сети документами CA обязан проделать некоторые подготовительные действия для получения исходных данных для поиска. Таковыми действиями являются определение языка документа, определение кодировки документа, возможно определение темы документа, если мы наделим CA соответствующими знаниями. Документ должен быть разобран на лексемы с учетом знаков препинания и пр., а результаты где-то отложены для их дальнейшего использования. При этом неплохо было бы иметь некое общее и достаточно вместительное хранилище, куда можно было бы положить оригиналы документов в том же виде, в каком их получил CA. Возможно, в дальнейшем мы придумаем новые методы обработки полученных документов, поэтому сохранение оригиналов является также необходимым условием.
Очевидно, что для подобных задач не подходит компьютер агента накопления CA в силу своей ограниченности. На практике стоимость аппаратного обеспечения CA равна примерно $500 (типовая конфигурация описана выше), половину этой суммы составляет стоимость индустриального корпуса в стойку. Оптимизация по стоимости CA важна с той точки зрения, что их количество в системе будет расти пропорционально суммарному количеству сканируемых документов сегментов сети из расчета 500 тысяч документов в сутки на один компьютер CA. В то же время, выход из строя одного из CA не должен вносить никакого существенного влияния в целом на процесс накопления. Исходя из этого, делаем предположение, что для хранения объектов накопления следует обзавестись выделенным сервером или несколькими серверами, которые по вместительности будут значительно превышать CA. Мы называем такие сервера архивными (Archive Server). При условии, что данные на таком сервере могут храниться в компрессированном виде, нетрудно посчитать, что одного сервера с массивом RAID объемом в 500GB должно хватать примерно на коллекцию в 50 млн. документов (на практике возможно меньше, во всяком случае, мы не ошибемся сильно в порядке). Количество архивных серверов напрямую зависит от количества сканируемых документов и с течением времени будет медленно расти. Сферу ответственности архивных серверов можно определить конфигурационно в виде интервалов идентификаторов документов, за которые данный архивный сервер несет ответственность. Такая конфигурация может быть централизовано сохранена на диспетчере и выдана любому участнику поисковой системы по его запросу при условии, что запрос прошел соответствующую авторизацию:
Archiver-001 1-20000000 Archiver-002 20000001-40000000 Попробуем отобразить, во что превращается наша система накопления. С учетом всего сказанного выше схема может иметь вид:
3.2. Как организовать взаимодействие.
Мы выяснили, что механизм накопления данных имеет распределенную структуру и извлечение каждого документа сопровождается как минимум четырьмя сетевыми взаимодействиями: CA получает информацию от DS об объекте сканирования, CA извлекает объект сканирования с внешнего сервера, CA передает компрессированное содержание документа AS и CA сообщает о результатах работы DS, получая при этом описание нового объекта сканирования. Реально на один документ происходит больше взаимодействий с различными подсистемами знаний. Например, после сканирования ресурса с именем http://xxx.yyy.zzz может оказаться, что его содержание идентично содержанию ресурса, находящегося по адресу http://aaa.bbb.ccc, и какая-то подсистема должна это определить во избежание хранения ненужного количества дублей по характеристике MD5 документа. Заметим однако, что пока мы только рассматривали систему накопления, не касаясь других систем движка. Однако уже на данном этапе становится ясным, что для успешного взаимодействия компонент системы требуется некий общий язык, на котором смогут "разговаривать" ее элементы. Для этих целей был разработан специальный протокол Search System Transfer Protocol (SSTP), полная спецификация которого приведена в соответствующей документации SSTP/1.0. Желающие могут ознакомиться с ней в полном объеме. Здесь же приведем только его базовые положения.SSTP является текстовым протоколом. Связано это с тем, что архитектура вычислительной техники может быть различной, и двоичные данные интерпретируются такими компьютерами по-разному. Протокол очень напоминает известный HTTP-протокол как протокол запросов и ответов. В рамках протокола сообщение состоит из заголовка, описывающего код запроса, типы данных и прочее в виде привычных пар параметр:значение. Коды запросов и ответов стандартизованы и полностью описаны в документации на SSTP, равно как и обозначения параметров и их возможные значения для различных кодов запросов. Все коды запросов и ответов HTTP входят в спецификацию SSTP без изменений. В рамках одной сессии возможно прохождение нескольких запросов и ответов. Несмотря на свою текстовую природу, SSTP позволяет передавать и двоичные данные, при условии, что полное описание их структуры содержится в текстовой части заголовка. Заголовок от данных отделяется пустой строкой (последовательностью символов CR/LF/CR/LF). Передача двоичных данных будет в дальнейшем рассмотрена на примере взаимодействия нескольких Процессоров Поиска (Search Processors) в процессе нахождения результатов, соответствующих поисковым критериям. Пока этих знаний нам достаточно.
3.3. Некоторые соображения о распределенности накопления.
Так как мы хотим построить движок, ориентированный на громадное количество документов, то мы должны быть готовы к затратам на их накопление. Под затратами в данном случае будем понимать оплату оборудования сканеров CA, диспетчера и архивных серверов, оплату каналов связи, оплату операторов, обслуживающих весь этот процесс. В масштабах мировой паутины можно получить впечатляющие цифры затрат. Как попытаться их минимизировать?Если модель накопления данных имеет распределенный характер, то почему не позволить другим компаниям-партнерам заниматься таким накоплением и обработкой результатов, сохранив за собой роль координатора в лице центрального диспетчера. Вы спросите, а какой резон партнерам участвовать в подобной программе. Ответов несколько: во-первых, сканируя собственные ресурсы собственными силами, участник программы гарантированно имеет самые свежие данные о состоянии документов его ресурсов в центральной поисковой базе. Во-вторых, участник программы, установив и настроив программное обеспечение, поставляемое ему нами, может организовать собственную поисковую систему по собственным ресурсам, при этом не затратив денег на разработку собственного программного обеспечения. При желании мы можем даже взять на себя роль обучающего центра и/или поддержку локального индекса. В-третьих, распределение сфер ответственности может породить тематические коллекции документов и возможность поиска по ним, что является немаловажным фактором в условиях стремительного роста объемов информации. В-четвертых, подобный сервис может предоставляться как бизнес-услуга клиентам в центрах хостинга или сервис-провайдинга. При желании можно обнаружить и другие резоны, однако это является задачей маркетологов и серьезно не рассматривается в данном документе.
Из вышесказанного следует, что нашей задачей наряду с разработкой системного программного обеспечения поискового комплекса является также разработка прикладного программного обеспечения локального поиска для внешних компаний или лиц, принципы которого будут существенно отличаться от принципов поиска в основной поисковой системе, однако данные для этих различных поисков будут общими.
Отметим также, что в случае, когда накоплением данных по части коллекции документов занимаются внешние партнеры, в алгоритм работы их накопителей следует внести некоторые изменения. Эти изменения могут быть связаны с ограниченностью ресурсов партнера (например, нет возможности установить у себя многоязыковую версию или ширина канала связи партнер-базовая система "Turtle" не достаточна). При взаимодействии с внешним CA необходимо минимизировать количество соединений с подсистемами "Turtle". Специально для таких клиентов создан вспомогательный индексный сервер, с которым и контактирует CA внешней компании и который сам осуществляет все необходимые соединения с внутренними серверами системы по локальной сети для выяснения детальной информации о документе. Мы называем такие типы серверов Knowledge Server. Их количество в системе зависит от того, какое количество партнеров имеет проект и какой суммарный объем информации обрабатывает каждый партнер.
При организации коллекции по географическому принципу URL ресурса не всегда отражает географическую принадлежность. Существует множество российских сайтов, которые находятся в различных доменах первого уровня, отличных от домена "ru". Например, корпоративный сайт нашей компании имеет имя www.stack.net. Вносить руками все вновь появляющиеся в таких зонах сайты, которые удовлетворяют заданным критериям коллекции весьма трудоемко. Забегая вперед, отмечу, что для решения подобных задач в рамках прототипа нашей поисковой системы мы создали специальный Geo-Ip Server (GS), в функции которого входит определение соответствия между Интернет IP адресом и географическим положением его владельца.
Следует отметить, что система не может ориентироваться исключительно на внешние накопители данных и должна обладать достаточным набором собственных CA, чтобы избежать нежелательной зависимости от внешних, неподконтрольных нам факторов.
3.4. Извлечение новых объектов сканирования.
Нахождение новых объектов сканирования является массовой операцией современной поисковой системы. Мы возлагаем ответственность за этот процесс на агенты накопления CA. Каждую найденную ссылку в документе CA должен проверить на правильность, с точки зрения интернет-имени сервера. Для этих целей используется стандартный механизм DNS. Однако поисковые системы имеют некоторую специфику. Обычные DNS-сервера сообщают результат установления соответствия между логическим именем компьютера и его IP-адресом и заносят в свой локальный кэш этот результат только в том случае, если ответ был получен. Это свойство обычных DNS-серверов может существенно снизить производительность CA в случае, если рассматриваемая им страница содержит массу ссылок на другие страницы и при этом первичный сервер зоны, в которой располагаются данные страницы в данный момент по каким-либо причинам не доступен. Несмотря на жесткиеx требования построения системы DNS к первичным серверам, указанная ситуация возникает достаточно часто. Для предотвращения потерь времени на попытках установления соответствия недоступных в данный момент первичных серверов мы построили специализированный кэширующий DNS сервер, который хранит и информацию о недоступности зоны в течение некоторого интервала времени, по истечении которого ранее недоступный сервер вновь проверяется.3.5. Базовая функция поиска документов.
Подойдем к вопросу функционирования поисковой системы Web-ресурсов с противоположной стороны, предположив, что какая-то составляющая комплекса умеет создавать из данных, накопленных CA, пригодный для поиска индекс. Причем умеет это делать именно в таком виде, какой нам потребуется для оптимального поиска. Рассмотрим возможные способы его хранения, а также то, как механизмы поиска будут связаны с выбранным способом хранения индекса. В качестве элементов прикидки будем использовать все те же оценочные характеристики русскоязычного сегмента сети Интернет.Анализ различных существующих реализаций полнотекстового поиска (а именно таковой мы проектируем) показывает, что в зависимости от полноты сохраняемой информации, методов хранения, дополнительных данных хранения и т.п. результирующий суммарный объем индекса может составлять от 15 до 200 % от суммарного количества исходных данных или, в нашем случае, от суммарной длины документов сканирования. Предположим достаточно оптимистично, что мы выбрали такую модель индекса, которая обеспечивает его суммарный размер на уровне 30% от общего размера документов. В пересчете на рассматриваемый нами российский сегмент сети Интернет предполагаемый размер индекса составит 70млн.*25КБ*30/100, или чуть более половины терабайта.
Вот с таким объемом информации нам придется быстро работать, при условии, что мы строим поисковую машину для России. Страшно подумать, что же будет в масштабах всего мира? Очевидно по многим соображениям, что такой индекс следует "размазать" по нескольким серверам по соображениям физической вместимости, быстродействия, способности к реплицированию, возможности параллельной обработки и пр. Чтобы понять, как индекс вообще можно разделить по нескольким серверам, сначала опишем информацию, которую должен содержать в себе этот индекс.
Ключом для поиска всегда является поисковый термин, или лексема. Индекс должен содержать информацию о номерах документов (ID), в которых данный поисковый термин встретился. Кроме того, индекс должен содержать координатную информацию слова в каждом конкретном документе.
Кстати говоря, когда мы разрабатывали в 1996 году поисковую систему Рамблер, то в силу ограниченности материальных ресурсов индекс не содержал координатной информации. Тем не менее, поисковая система Рамблер долго показывала вполне сносные результаты и без него. Теперь, конечно, там все не так, однако полагаю, что программное обеспечение Рамблер нельзя смасштабировать до уровня мировой поисковой системы, оно просто на это не рассчитано. Впрочем, я могу ошибаться. Современные российские поисковые системы не очень охотно описывают свои "внутренности".
Неплохо было бы также наделить индекс некоей качественной информацией об уровне значимости данного поискового термина в рамках данного документа. Частота употребления термина, его положение в тексте, близость смежных терминов, способы выделения термина, цвет букв шрифта, если документ является HTML, и т.д. оказывают влияние на этот качественный показатель. Нельзя также забывать о мерах предосторожности против "находчивых" владельцев ресурсов, старающихся любым способом заставить поисковый движок показывать его документы первыми, даже в случае, если содержание текста документа далеко от соответствия данному поисковому термину. Также хотелось бы в индексе учесть и саму значимость документа с точки зрения всей коллекции документов: как часто цитируется данный документ и насколько авторитетны источники, которые на него ссылаются. Можно придумать еще массу параметров, содержащихся в индексе, однако вспомним о размере и пока ограничимся этим. Более подробно строение индекса и механизмы ранжирования будут описаны в дальнейшем.
В пределе простой индекс может содержать только сами слова и номера документов, в которых они содержатся. Такой индекс можно разбить по нескольким серверам только двумя способами:
И тот, и другой способ имеют право на жизнь. У каждого из них - свои достоинства и недостатки. Не вдаваясь в подробности анализа, отмечу, что мы выбрали первый способ разбиения индекса. Каждый из равноправных компьютеров процессоров поиска содержит информацию о терминах определенного диапазона. Вопрос лишь в том, как именно распределены эти диапазоны.
- Разбить поисковые термины на интервалы (скажем, по первым буквам).
- Разбить индекс так, чтобы в пределах одного сервера содержались все термины, относящиеся к определенному диапазону номеров (ID) документов.
Для правильного разделения индекса по первой модели следует осознавать, что, с одной стороны, индекс должен быть разбит примерно на равные части по размеру, чтобы уравновесить конфигурацию типового компьютера для поиска. С другой стороны, количество суммарных обращений к каждому из серверов для хорошей нагрузочной способности должно быть примерно равным, чтобы уравновесить в целом поисковую систему. Нельзя допускать ситуации, в которой один из поисковых серверов постоянно загружен, а другой простаивает.
Первый параметр разбиения индекса определяется частотностью слов в документах, второй - частотностью слов в запросах пользователей. К счастью, мы владеем соответствующими данными и имеем оценочные характеристики обоих параметров в условиях российского Интернета. Если же мы соберемся перестроиться на систему мирового масштаба, то, наряду с увеличением процессоров поиска нам также потребуется выбрать иные интервалы разбиения индекса, исходя из реалий жизни. Однако это никаким образом не повлияет на программное обеспечение поиска.
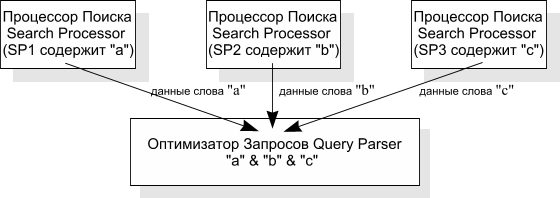
Попробуем представить примерную схему поисковой работы с таким индексом. Предположим, что нам требуется найти документы, содержащие слова "a", "b" и "c" одновременно. Предположим также, что индекс слова "a" находится на поисковом процессоре SP1, индекс слова "b" - на SP2, "c" - на SP3. Первоначальная схема поиска может выглядеть примерно так:
В этом случае все данные о каждом поисковом термине "a", "b" и "c" передаются на внешнюю программу, на которой производится выбор ID-документов, которые удовлетворяют всем условиям.
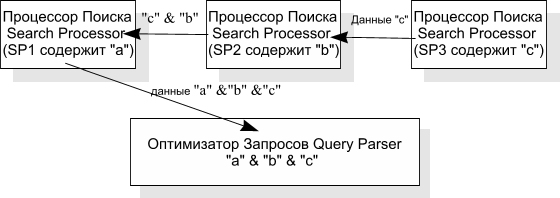
Эту же работу можно выполнить иным способом, например, так:
Данный пример отличается от предыдущего тем, что по сети мы передаем значительно меньше данных, т.к. от SP2 к SP1 уже следует пачка идентификаторов ID, удовлетворяющая условиям "c" И "b" в одном документе. От SP1 к разборщику запросов "едет" чистый результат логического пересечения всех ID. Однако, для реализации этого механизма нам необходимо "научить" взаимодействовать SP друг с другом в рамках разработанного нами протокола SSTP. Ну и кроме того, SP должен являеться не просто хранителем индекса, но и обязан "уметь" осуществлять требуемые логические операции. Сейчас в арсенале SP реализовано 8 различных операций с данными по поисковым терминам, среди которых есть экзотические типа "исключающее ИЛИ".
Теперь представим себе на минуту, что размер индекса слова "c" значительно превышает размер индекса слов "b" и "a". В таком случае очевидно, что выбранная схема поиска не является оптимальной. Оптимальней было бы получать результаты от SP3, т.к. при обратной схеме потоков данных о словах нам бы пришлось передавать по сети от одного поискового процессора к другому меньше данных. Нетрудно понять, что в случае логического поиска документов, содержащих все поисковые термины, выгодно выстраивать именно цепь взаимодействий, т.к. каждый промежуточный результат будет по своему объему меньше, чем предыдущий. При поиске документов, содержащих любой термин, выгоднее собрать информацию по каждому из них в общей точке и там произвести объединение, т.к. после каждой элементарной операции объединения количество результатов будет превышать исходное.
В общем случае поисковый запрос может иметь весьма сложную структуру с учетом морфологических форм и языка запроса и выполняется различными способами. Логические схемы выполнения сложного поискового запроса могут быть представлены сложными деревьями с закольцованными взаимодействиями. Напрашивается вывод, что кто-то должен, проанализировав исходные данные, для каждого конкретного поиска выбрать наиболее оптимальный по времени способ выполнения. Эти задачи мы возлагаем на разборщик запросов Query Parser (QP). Из всех возможных вариантов выполнения данного запроса он выбирает самую быструю схему и согласно этой схеме составляет программу работы всего поискового комплекса для выполнения задачи.
Для того чтобы различные SP могли взаимодействовать друг с другом, в рамках протокола был разработан язык выполнения поисковых программ Search System Assembly Language, который содержит набор директив каждому конкретному SP. Программа, написанная на этом языке, формируется на QP с учетом оптимизации ее выполнения по времени и передается на выбранный SP. Это настоящий специализированный язык программирования, содержащий в себе два десятка операторов, включая операторы условного перехода. С технической документацией на SSAL можно познакомиться здесь.
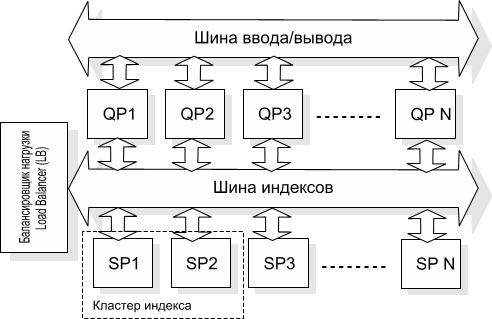
Если в рамках поисковой системы возникает ситуация, когда набор SP, содержащий полный индекс базы (мы называем его кластером индекса), не успевает обработать все входящие запросы, то это означает, что нам пора ввести еще один кластер, содержащий полный индекс, вернее, точную его копию. Он может архитектурно отличаться от уже существующего (например, быть выполнен на платформе DEC, а не Intel, но лучше все же придерживаться одной архитектурной линии. Мы выбрали для себя Intel-платформу, наиболее точно для нас отражающую соответствие цена/качество).
Нетрудно заметить, что при обработке одного запроса не всегда в работе принимает участие весь поисковый кластер. Запрос из одного слова всегда обрабатывается только одним процессором поиска при выбранном нами способе разбиения индекса, все остальные в данный момент времени являются свободными. Отсюда можно сделать вывод, что архитектура фиксированных или статических кластеров индекса не является самой оптимальной.
Введем понятие динамического кластера индекса. Динамическим кластером индекса будем называть совокупность свободных (или наименее занятых) в данный момент процессоров поиска SP, формируемых внешней программой для выполнения конкретного поискового запроса. Очевидно, что сформировать такой динамический кластер может программа, которая имеет представление о состоянии каждого процессора поиска системы. Мы называем такой сервер балансировщиком нагрузки Load Balancer (LB). Этот сервер способен держать в памяти текущие и планируемые состояния каждого из SP и по запросу оптимизатора QP выдавать динамическую конфигурацию кластера индекса для выполнения поискового запроса.
Итак, как видим, что для поддержания базовой функции поиска в архитектуре нашей поисковой системы нам необходимы еще три типа серверов. Это оптимизатор запросов Query Parser, поисковый процессор Search Processor и балансировщик нагрузки Load Balancer. Результирующая схема поисковой машины с полюса поиска может выглядеть пока так:
3.6. Как на практике предсказать время выполнения запроса.
Оптимизатор запроса QP должен вычислить примерную продолжительность выполнения поискового запроса различными способами и выбрать наиболее оптимальную схему. Эти данные он потом сообщает балансировщику нагрузки. В качестве исходных данных для вычисления он использует оптимизированную им же программу выполнения запроса, количество данных по каждому поисковому термину, местоположение индекса (на каком из серверов находится индекс данного слова). При этом известна средняя скорость чтения данных с диска, известна скорость передачи данных по локальной сети и известно среднее время установления головок системы в необходимое для чтения состояние.Пикантность вопроса заключается лишь в том, как организовать общее для оптимизаторов хранилище памяти, в котором будут указаны размеры данных поисковых терминов. Количество возможных лексем для происка с учетом орфографических ошибок, сокращений, абревиатур и пр. составляет примерно 40 миллионов. На практике нет необходимости хранить длину данных каждого поискового слова. Достаточно лишь выбрать правильный критерий размера, начиная с которого длину данных следует учитывать при оптимизации запроса. Данные по остальным поисковым терминам в силу их небольшого размера следует положить некоей константой. Этот барьер подбирается экспериментально в зависимости от размера коллекции, точнее, от количества уникальных слов, пригодных для индекса. При этом барьер занесения поискового слова в такую таблицу выбирается с учетом того, чтобы использовать только ограниченное, разрешенное администратором количество памяти на компьютере, на котором работает каждый QP. С помощью специальной программы такой сегмент общей памяти строится один раз в разумный интервал времени (например, раз в месяц) и загружается во время запуска операционной системы компьютера оптимизаторов запроса. Нет необходимости иметь абсолютно точные значения длины данных поискового термина, достаточно иметь приблизительные или оценочные величины.
3.7. Ранжирование результатов.
Предположим, что функции поиска мы полностью реализовали и теперь нам требуется расставить найденные документы в правильном порядке; первые документы, по мнению поисковой системы, должны наиболее точно соответствовать поисковому запросу. Функция такого ранжирования всегда является базовой для любой поисковой системы. По качеству ранжирования пользователи судят в целом о качестве поисковой системы. Существует множество описанных методов, суть которых сводится к одному - каждому найденному по запросу документу следует поставить в соответствие некое характеристическое число и отсортировать выборку по убыванию этого весового коэффициента.В базовой модели поиска системой "Turtle" заложен принцип использования различных параметров, которые оказывают влияние на результаты ранжирования. В общем случае формулу для вычисления характеристики документа в результатах поиска можно представить так:
RL(x) = K1*PP(x) + K2*PT(x) + K3*PR(x) + K4*CO(x)+...
Заметим, что в конце формулы мы поставили многоточие. Этим мы хотим обозначить тот факт, что при разработке нового метода ранжирования мы будем способны ввести такой новый фактор в наши вычисления результирующей функции ранжирования.
- где
- RL - результирующая релевантность документа х;
- PP - предвычисленная характеристика частотности термина в документе х;
- PT - предвычисленная характеристика местоположения термина в различных полях HTML-тэгов документа (если документ является HTML);
- PR - PageRank данного документа, согласно определению. Эта величина не зависит от содержания запроса;
- CO - функция, учитывающая координатное положение внутри документа терминов поискового запроса;
- K1-K4 - нормировочные коэффициенты для соответствующих функций.
Так, например, мы до конца для себя не решили, стоит ли учитывать слова, находящиеся в поле ссылки, для ссылаемого документа. С одной стороны, автор документа, содержащего такую ссылку, явно ее назвал. Слова, обрамляющие данную ссылку, могут быть привязаны к тому документу, на который ссылается данный текст. Однако на практике часто бывает, что документ ссылается на головную страницу новостного ресурса, который более не содержит данной рубрики в себе. Кроме того, учитывая слова ссылок, мы добавим в систему некий фактор субъективизма человека, который написал исходный документ, и перенесем этот фактор на ссылаемый документ. Поясню свою мысль на простом примере. Предположим, что в нашей гипотетической базе данных имеется всего три документа, два из которых ссылаются на третий. В первом документе ссылку на третий документ обрамляют слова: "прекрасный документ". Второй документ ссылается на третий словами: "безобразный документ". По каким ключевым словам мы найдем третий документ в данной системе и удовлетворят ли нас результаты найденного? Пример, конечно, надуман, но не так далек от реальной жизни. Так, например, одна известная поисковая система по Web-ресурсам, использующая механизм ссылок слов других документов, на запрос, состоящий из выражений ругательного характера, первой же ссылкой результатов поиска выдавала название крупнейшей компании по производству программного обеспечения. Хорошо это или плохо, судить пользователям поисковой системы. В любом случае, технически проделать это в рамках представленного прототипа довольно просто. Главное, постараться правильно формализовать степень влияния таких слов.
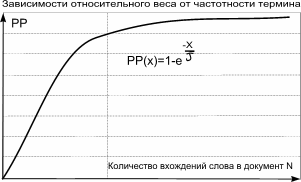
Несмотря на то, что компоненты формулы входят в нее как линейная комбинация с соответствующими коэффициентами влияния, каждая из этих функций не является линейной. Так, например, функция, учитывающая частотность термина в пределах документа имеет вид:
Одной из компонент результирующей релевантности является очень модный сейчас термин "PageRank" в его классическом определении, которое я не стану приводить здесь. Некоторые полагают, что использование PageRank поисковой системой Google является решающим фактором в соревновании качества поисковых машин. Конечно, использование ранка документов является важным элементом ранжирования, однако назвать его решающим я бы не рискнул. На мой взгляд, это всего лишь одна из нескольких составляющих ранжирования, ни больше, ни меньше.
Как видно из приведенного графика, результирующая функция ведет себя линейно до некоторой точки в зависимости от количества вхождений слова. После прохождения этой точки увеличение количества терминов не вносит существенных изменений в значение результата. Это можно рассматривать как один из способов борьбы с искусственным завышением функции релевантности хозяевами ресурсов. Значение коэффициента T может изменяться в зависимости как от размеров коллекции, так и от смыслового поля HTML документа (или любого другого типа документа, содержащего в себе структурные части текста). На практике мы используем множество таких методов и не станем приводить здесь их описание. Несколько слов для непосвященных. Метод вычисления PageRank основан на построении графа, узлами которого являются идентификаторы документов коллекции, а ребрами являются ссылки документов друг на друга. После построения такого графа производится вычисление весов узлов в зависимости от количества входящих и исходящих ребер, согласно определению. Здравый смысл подсказывает, что чем больше документов ссылается на какой либо конкретный документ, тем больше его значимость для коллекции в целом. Беда заключается в том, что для вычисления PageRank результирующий граф должен быть полностью связанным, чего в реальной жизни, увы, не происходит. Существуют методы и алгоритмы для выделения сильно связанных компонент таких графов. Их может оказаться несколько, и манипуляции с такими компонентами являются ноу-хау каждой из поисковых систем. Переоценка важности фактора PageRank может привести к различным казусным ситуациям. Известны случаи, когда владелец сайта-форума помещал на каждой его странице ссылку на сайт друга, обрамленную одними и теми же словами. Форум имел достаточно оживленную дискуссию и сайт друга владельца неизменно поднимался в результатах поиска поисковой машины, использующей фактор PageRank как решающий при вычислении релевантности.
Однако, вернемся к результирующей формуле релевантности. Особо обращаю внимание на то, что правильное определение нормировочных коэффициентов для каждой из составляющих результирующего значения ранжирования на практике является настоящим искусством. Эти коэффициенты учитывают как объективные факторы влияния термина на документ, так и субъективные. По этой причине, хранение весовых характеристик разного физического смысла следует осуществлять раздельно и "смешивать" их в определенной пропорции только на завершающем этапе поиска перед сортировкой результатов.
Кстати, о сортировке. Алгоритмы сортировки современной поисковой машины могут (и должны быть) разными в зависимости от того, какое количество результатов было найдено и какое количество результатов реально требуется. Предположим, что в результате выполнения поискового запроса был найден 1 миллион ссылок. Нет смысла сортировать весь этот набор данных. В самом деле, какая вам разница, какой документ будет на 500001 позиции, а какой на 500002, если вы собираетесь просмотреть только первые 500. Мы проектируем поисковую машину для живых людей. Исходя из этого, достаточно правильно отобрать требуемое количество наилучших результатов, а уже их потом отсортировать. Подобные механизмы сортировок были разработаны в нашей компании Федором Сигаевым. Они с успехом находят применение и в других программных продуктах, например, используются в СУБД PostgreSQL http://www.postgresql.org/. Универсализм в подходах к решению разноплановых задач хорош с точки зрения компактности кода, но никак не с точки зрения быстродействия.
3.8. Некоторые замечания о поиске (кэш, отображение, дубли, ссылки).
Все вышесказанное найдет отображение на результирующей функциональной схеме поискового комплекса.
- Замечание 1.
- Обратим внимание на то, что языки, на которых мы разговариваем, хотим мы этого или нет, имеют ограниченный набор слов. Некоторые слова используются при поиске различными людьми часто, другие значительно реже. Для частых слов можно предусмотреть сервер, который собирает результаты таких запросов. В этом случае при повторном запросе нет необходимости "ставить на уши" весь набор поисковых серверов, достаточно взять полученные результаты у этого сервера. Мы называем такой сервер кэширующим (Results Cache Server). Этот же сервер может применяться для отображения второй, третьей и.т.д. страницы результатов поиска. По данным такого сервера можно динамически наблюдать за введенными пользователями запросами (у некоторых поисковых систем есть функция - показать 20 последних запросов к системе. Мы также можем отобразить подобную информацию, используя специальный запрос к Cache Server). Программно он может быть реализован как независимая единица или войти в состав сервера балансировщика нагрузки (мы имеем оба варианта). В поисковой системе, кроме специального кэша результатов, реализован также кэш наиболее часто "поднимаемых с диска" поисковых терминов на каждом процессоре поиска SP. Дело в том, что очень часто возникает ситуация, когда пользователь повторно нажимает кнопку поиска по ошибке или недождавшись выполнения посланного им запроса. При этом навигационная программа пользователя добросовестно игнорирует предыдущее соединение и снова посылает поисковый запрос. Мы называем такой эффект электронным термином "дребезг контактов". Кэш поискового процессора предотвращает повторное чтение данных с дисковых массивов. Это может позволить существенно улучшить суммарную производительность системы.
- Замечание 2.
- В приведенной выше схеме поиска начисто отсутствует отображение результатов. Мы же не можем показать конечному пользователю набор ничего ему не говорящих цифр ID-документов. Мы должны показать фрагмент документа с ссылкой на оригинал, и желательно, чтобы фрагмент отображал часть текста, соответствующую поисковому запросу. Вспомним о том, что сами документы в процессе накопления мы складывали на архивных серверах. Таким образом, прослеживается первая ниточка между двумя крайними полюсами системы накопления и поиска. Архивный сервер умеет не только сохранять в специальном компрессированном формате исходный текст документа, но и отображать наиболее подходящий фрагмент текста. Этот тип серверов также наделен кэширующими свойствами. Он может отобразить документ даже в том случае, если оригинал уже был удален со своего сервера. На него также возлагаются функции ретроспективного просмотра документов, изменяющихся во времени.
- Замечание 3.
- В сетевом мире содержится много документов, которые не являются точными копиями друг друга. Такие документы могут содержать общие фрагменты или не очень сильно отличаться по тексту. Если в результатах поиска такие документы будут показаны вместе, то это вызовет у искавшего, как минимум, легкое раздражение. Для выявления нечетких дублей нами разработана специальная технология, основанная на выделении некоторого набора характеристических цифр (fingerprints) для каждого документа. Разработаны также быстрые алгоритмы работы с подобными типами данных. Используя эту технологию, можно с достаточно высокой степенью достоверности выяснить, является ли один документ схожим с другим. Для подобных целей нами разработан специальный сервер Fingerprints Server (FPS). Его назначение состоит в том, чтобы отфильтровать из пачки документов похожие. Исходными данными его снабжают накопители данных CA, описанные в начале. Запросы фильтрации на такой сервер посылают разборщики запросов QP после получения результатов работы от процессоров поиска. Таким образом, в целом в поисковой системе реализована двухуровневая модель выявления дублей. Первая - на основе точного совпадения содержания посредством технологии вычисления MD5-документов. Вторая - на основе фингерпринтов. Технологию фингерпринтов можно также успешно применять для обратной задачи - поиска "похожих" документов. Отметим, что в данном случае под похожестью мы понимаем наличие какого-то количества общего текста в документах. Технология поиска "похожих" документов позволяет проделывать массу, на первый взгляд не очевидной, полезной работы. Например, с помощью данной технологии можно по достаточно длинной цитате найти ее первоисточник в оригинале, разумеется, если оригинал представлен в сети в виде документа. Или разыскать документы, цитирующие содержание оригинала, найти потенциальный плагиат и пр.
Отметим, однако, что механизм поиска подобных по содержанию документов с разным лексическим составом не может быть реализован с помощью этой технологии, т.к. имеет совсем иную природу и основывается на выделении значимых понятий и терминов в документе, их сочетаний и поиска подобных сочетаний по другим документам коллекции вместе и по отдельности. Подобные механизмы реализованы во многих поисковых системах, и, по моему мнению, везде они реализованы достаточно плохо. Полагаю, связано это прежде всего с тем, что очень трудно формализовать то, что система будет называть "подобными" документами, и будет ли это определение устраивать нас как пользователей поисковой системы, в каждом конкретном случае поиска подобных документов.
- Замечание 4.
- Здесь мы рассмотрели только примерный механизм поиска в рамках поисковой системы "Turtle". Механизм поиска по локальным коллекциям, который мы собираемся поставлять в виде программного обеспечения желающим, выстроен совсем по другим принципам, т.к. хранилище данных имеет простую структуру.
- Замечание 5.
- Если конечный пользователь пожелает узнать, какие документы ссылаются на данный документ, то описанный индекс, распределенный по группе SP, не сможет ответить на данный вопрос. Поэтому в поисковом комплексе имеется специальный сервер ссылок References Server, который содержит информацию о ссылках. Этот сервер в процессе работы накопления взаимодействует с центральным диспетчером посредством SSTP-протокола и получает от него требуемые данные. Хранимые на нем данные, помимо визуализации подобных связей, участвуют также в вычислении одной из компонент ранжирования документов PageRank.
3.9. Язык поисковых запросов.
При реализации интерфейса с пользователем поисковой системы мы предусмотрели несколько видов такого взаимодействия:Коротко остановимся на последнем. Разработанный нами мощный язык поисковых запросов Turtle Search System Query Language (TSSQL/1.0) позволяет выполнять запросы по полнотекстовой поисковой системе практически любой сложности. Полное описание языка запросов приведено здесь. Отметим только один момент. Использование языка запросов, помимо своих прогрессивных и гибких функций, имеет и некоторые негативные моменты в целом для поисковой системы. Дело в том, что запросы с использованием языка часто предусматривают строгую последовательность действий над поисковыми терминами, что приводит к практической невозможности оптимизации подобных запросов по времени. Поэтому мы считаем, что по умолчанию подобная функция должна быть выключена в интерфейсе пользователь-"Turtle" и может активизироваться самим пользователем по желанию, когда он чувствует потребность в использовании языка запросов.
- Простая форма запроса. Большинство параметров поиска установлено в наиболее пригодные для всех значения по умолчанию.
- Определение параметров пользователя с помощью механизма идентификации.
- Форма расширенного поиска. Позволяет сочетать в себе различные комплексные запросы с настройкой многих параметров поиска.
- Использование языка запросов поиска.
В будущем возникнут и другие интерфейсы взаимодействия пользователя с поисковой системой. Я не имею ввиду модификацию уже упомянутых способов, как встраивание поисковых форм в другие интегральные средства навигации по документам сети и пр. Очевидно, что в рамки предложенного прототипа легко укладываются преобразователи речи в формальное представление запроса с помощью внешних модулей. Вопрос лишь в том, на сколько "правильно" будут реализованы данные преобразователи.
3.10. Индекс, подготовка данных для поиска.
Теперь рассмотрим уже упомянутое мною недостающее звено в цепи накопления данных - поиск по данным. Хочу особо обратить внимание на тот факт, что мы, разработчики этой системы, должны ввести понятие максимального времени отклика системы при поиске. Это означает, что результаты поступают на экран не позднее, чем через определенный интервал времени, и желательно, чтобы этот интервал был как можно меньше. Однако что делать в случае, если поисковый запрос содержит очень частотные поисковые термины? Передача большого количества данных с одного процессора поиска на другой определяется скоростью среды, к которой подключены компьютеры этих серверов (обычно это 100 Mb или 1Gb), и не может быть уменьшена в рамках конкретной технической реализации. Из этого факта следуют два принципиальных вывода:С первым пунктом все понятно - требуется работа квалифицированных инженеров. Остановимся на втором пункте. Частотным термином будем называть слово, которое встречается в таком количестве документов, передача данных для которого с одного процессора поиска на другой превысит предельную величину времени в одну секунду.
- Необходимо тщательно проектировать топологию подключения серверов поисковой системы, во избежание конфликтов между потоками.
- Необходимо постараться минимизировать количество передаваемых данных в условиях запросов частотных терминов.
Предположим, что частотные слова распределяются равномерно в рамках всей коллекции документов. На практике это означает, что количество документов в интервале идентификаторов ID от 1 до 1000000, содержащих частотное слово "a", примерно равно количеству документов, содержащих это же частотное слово в интервале ID от 1000000 до 2000000, и так далее.
Сделаем предположение, что само по себе частотное слово является малоинформативным именно потому, что встречается в большом количестве документов разных тематик. Следовательно, для получения результатов сложного запроса, содержащего частотные слова, можно попытаться оперировать не полной информацией по частотному слову, а только ее частью, и в дальнейшем апроксиимировать количество суммарных результатов.
Мы храним индексную информацию по частотным словам некими фиксированными порциями, которые назвали "корзинами". Если оптимизатор запросов в своих расчетах убеждается, что для выполнения запроса полностью потребуется слишком много времени, то он старается составить план запроса таким образом, чтобы у частотных слов читать из индекса только ограниченное количество информации (корзин), при котором выполнение запроса не превысит некоей критической величины по времени. Ограничивая количество данных для частотных слов, система практически не ухудшает своих релевантностных характеристик, т.к. влияние самих частотных слов обычно минимально. Исключения составляют только те запросы, которые состоят только из частотных слов. Однако простая логика подсказывает, что подобные запросы обычно не имеют смысла. В качестве исключения из этого правила можно привести шекспировское "to be or not to be". Количество таких запросов не превышает сотой доли процента от общего количества, и мы решили не "ломать копья" за их удовлетворение. Для подобных запросов был разработан специальный алгоритм выбора количества корзин, однако на практике можно выбрать корзины случайным образом.
Полагаем, что каким-то подобным способом ограничивается количество частотных поисковых данных и в других системах (например, Google), которые в результатах поиска отображают примерное количество найденных результатов. Особенностью системы "Turtle" является то, что она будет стараться использовать не фиксированное количество данных для частотных поисковых слов, а максимально возможное, с учетом реалий запроса. Становится понятным, что следует понимать под стабильностью результатов поисковой машины и почему один и тот же запрос может в течение времени получить немного разные ответы. Следует также отметить, что понятие частотного слова может возникнуть при условии, что коллекция документов поисковой системы весьма велика. Если коллекция будет ограничена (например, пределами российского Интернета), то можно смело утверждать, что количество частотных слов в системе будет не так велико (или их вообще не будет).
Теперь можно описать устройство самого индекса, а также программ, которые его создают. Анализируя два возможных способа хранения поисковых терминов (лексем) в базе данных, мы для себя не обнаружили существенных решающих преимуществ хранения цифровых обозначений (ID) лексем перед хранением самих лексем. Например, хранение лексем в виде их идентификаторов лишает нас возможности искать по двоичному дереву лексемы, имеющие произвольное окончание без специальных внешних процедур.
В нашем случае индекс имеет двухуровневую структуру. Первый уровень содержит бинарное дерево поисковых терминов в качестве ключа поиска. В качестве аргументов такого ключа используются данные по полному индексу, а именно: координата в индексном файле начала данных, длина данных, компрессированная длина данных, количество корзин данных, номера URL начала и конца каждой корзины. Запись двоичного дерева имеет вид:
Если слово является частотным, то данные для него хранятся в нескольких корзинах, и в базе BTREE-лексем содержится описание каждой корзины с данными. Поле "Position" указывает на координату в файле собственно самих данных индекса данного слова. Файл данных индекса слов является вторым уровнем индекса. Хранение данных в нем производится следующим образом:
Основные компрессированные данные
Main compressed dataРасширенные компрессированные данные
Extended compressed dataКак видно из схемы, реальные данные по поисковому термину состоят из двух частей, каждая из которых сохраняется в компрессированном виде. Зачем мы разделили данные на две отдельные части, а не компрессировали их вместе? Дело в том, что основная часть поисковых запросов по умолчанию не использует данные расширенной части. Они используются для искусственного ограничения области поиска (например, искать только в заголовках и пр.), и не должны считываться с диска в условиях типового запроса. Основной частью данных является первая компрессированная пачка данных, содержащих в себе структуры ID-документов, предвычисленные веса для данного поискового термина в пределах этого ID, предвычисленный на момент сканирования PageRank документа указанного ID и координатную информацию по каждому термину, включая номер фразы текста (мажор) и номер слова внутри фразы (минор). Для оптимального использования дискового пространства данные с плавающей точкой хранятся с уменьшенным количеством разрядов. Не каждая пачка информации является компрессированной, программно устанавливается предельный барьер количества данных, начиная с которого данные будут компрессированы. Это предотвращает большое количество малоэффективной работы по слабочастотным лексемам.
Для эффективной поддержки файла данных индекса нами был разработан специальный диспетчер свободного места в файле индекса. Дело в том, что в процессе обновления данных сканирования часть терминов исчезает из документов, в то же время появляются новые термины. В целом природа данных поискового термина имеет возрастающий во времени характер с учетом увеличения числа сканируемых системой документов. При обновлении индекса ранее используемое место освобождается и новые данные укладываются начиная с позиции, указанной таким диспетчером. Ему же система сообщает о координатах и размерах освободившихся кусков. В целом, используя подсистему менеджера свободного места в индексном файле каждого отдельного процессора поиска, можно достаточно долго не проводить полного перестроения индекса. Сигналом к его полному перестроению является превышение общего размера индекса к его полезной части на уровне 1.7.
3.11. Борьба за компактность. Компрессия.
Казалось бы, что здесь рассуждать? Так как мы строим высокотехнологичную систему, способную индексировать данные мировой паутины web-документов, то в целях экономии места в хранилище индекса также, как и при сохранении самих образов документов, следует использовать один из методов компрессии. Не торопитесь делать поспешные выводы.Мы провели некоторые исследования поведения различных доступных нам реализаций компрессоров данных. Эти исследования говорят о том, что в использовании методов компрессии для работы с поисковым индексом не все так однозначно. Так, например, скорость сжатия данных при помощи библиотеки функций GZIP (ZLIB_VERSION "1.1.4") составляет около 1MB в секунду, а скорость обратной операции извлечения данных составляет около 20MB в секунду на доступном нам реальном железе. Вспомним о том, какими объемами данных нам приходится оперировать для построения индекса. Реально для российской модели поиска, упомянутой в начале, это означает, что если мы производим обновление индекса, в котором информация хотя бы по половине поисковых терминов изменилась (суммарный объем половины данных индекса положим равным 250GB), то на разбор этой пачки мы потратим три с половиной часа, а на сбор новой пачки еще трое суток. А ведь это не самая важная операция обновления индекса.
Вспомним также о том, что мы поставили задачу: как можно быстрее обслужить поисковый запрос. Применительно к данным по частотным словам, такие задачи явно противоречат попытке экономии места за счет компрессии, т.к. скорость декомпрессии уступает скорости чтения с диска (или массива дисков). Если взять для рассмотрения "среднюю" корзину данных в 10МБ, то только на ее разбор потребуется полсекунды. При этом мы собираемся потратить на исполнение всего запроса несколько секунд, максимум.
Кроме того, на разных типах данных разные методы могут показывать различные временные и качественные показатели. Например, данные, полученные с помощью компьютерной генерации псевдослучайных чисел, вообще не поддаются сжатию, и понятно почему, они просто не содержат в себе регулярности. Впрочем, не все так печально. В любом случае, прежде чем принять решение об использовании компрессионных методов, следует попробовать эти методы на реальных данных индекса поисковой системы.
Какие практические выводы мы сделали?
В самом деле, никто не ставил задачу минимального времени отклика системы на поисковый запрос. Мы ставим задачу получения ответа на такой запрос в разумный интервал времени. Значит, компрессию данных применять можно, учитывая вышеизложенные соображения.
- Популярный пакет BZIP2 для данных задач использовать принципиально нельзя по причине плохих скоростных характеристик. По этим показателям он в 2-5 раз уступает GZIP, хоть и имеет некоторые преимущества в компактности.
- Компрессию в данных индекса использовать можно. Мы для себя выбрали функцию сжатия GZIP с уровнем 5. Программное обеспечение должно быть разработано таким образом, чтобы включение и выключение компрессии можно было бы производить конфигурационно, без полного перестроения индекса.
- Единицей для сжатия за одну операцию может являться "корзина" (или ее часть - см. выше). Существует некая критическая точка минимального размера данных для сжатия, ниже которой пытаться сжимать данные не имеет смысла (мы попусту тратим время без выигрыша дискового пространства).
- Существует вторая критическая точка размера данных "корзины", выше которой использование стандартных методов декомпрессии становится невозможным по причине того, что при поиске мы не сможем уложиться в заданный максимальный временной интервал.
- Для больших "корзин" можно использовать компрессоры, имеющие худшую степень сжатия, но лучшую скорость компрессии/декомпрессии (нами был выбран один из методов библиотеки LZO lzo-1.07.tar.gz).
Оговорюсь в конце, что здесь мы говорили об исследованиях компрессии данных без потерь информативности и, исключительно, применительно к реальным двоичным данным нашего индекса "Turtle". Возможно, при проектировании другой поисковой системы с другой архитектурой результаты будут иными. С отчетом, содержащем таблицы замеров и графики, об исследовании методов компрессии, применительно к нашему случаю, можно познакомиться здесь.
3.12. Построение и обновление индекса.
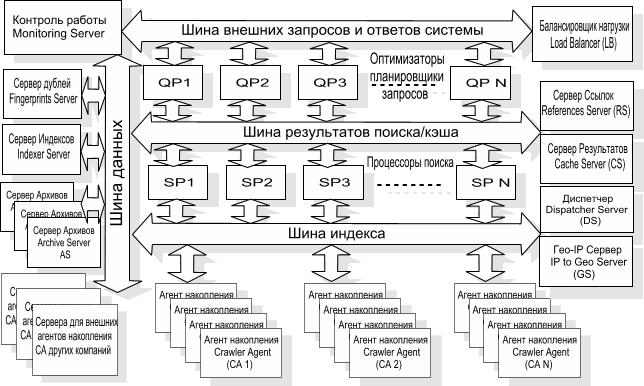
Настало время описать, каким образом мы формируем новые данные для индекса. Как отмечалось ранее, каждый агент накопления CA в процессе своей работы откладывает во временное хранение промежуточные результаты сканирования. Важнейшими из них являются списки выявленных лексем с сопутствующей информацией. Введем понятие индексирующего сервера Indexer Server (IS). В какой-то момент времени этот сервер посылает по сети сигнал всем CA о том, что собирается забрать у них накопленные данные. По этой команде каждый CA осуществляет сортировку накопленных данных для того, чтобы в дальнейшем IS мог легко объединить эти данные и сформировать результирующие пачки данных. Данные забираются на IS и объединяются там при помощи специально разработанной сетевой версии программы слияния сортированных данных (merge sort). После этого по полученным данным строится индекс, который разбивается на составные части по законам, определяющим разбиение на группы SP-индекса. IS формирует очереди данных индекса для каждого SP, после чего начинает синхронную передачу сформированных данных на все SP. На стороне SP эти данные принимает специальная программа, в состав которой входит менеджер свободного места индекса. Отметим, что при подобном методе обновления индекса мы достигаем параллельности работы CA при сортировке данных и параллельности работы SP при приеме новой порции индекса, что позволяет существенно сократить время общего обновления индекса.С учетом всего описанного выше, результирующая структурная схема поисковой системы "Turtle" имеет вид:
4. Масштабируемость. Описывая строение и функции различных подсистем, мы несколько раз вкратце упоминали о функциях масштабируемости системы. Суммируем эти соображения. С ростом количества сканируемых документов в рамках системы следует удерживать время полного цикла сканирования на допустимом уровне. Для решения этой проблемы предполагается увеличивать количество накопителей данных CA, которые имеют скромную конфигурацию и достаточно дешевы. Их работу обслуживает и обеспечивает центральный диспетчер. В существующей реализации, полагаю, это является одним из слабых звеньев. Масштабирование количества диспетчеров следует спроектировать в будущем. Пока же экспериментальные данные говорят о том, что один диспетчер способен обеспечить накопление порядка 50 млн. документов в сутки множеством CA. Сейчас эти цифры являются удовлетворительными даже для масштаба всей сети Интернет, однако сеть бурно развивается, и работу над масштабированием этого звена следует проводить уже сейчас. Распределенный принцип работы диспетчеров внесет свои изменения в логику работы некоторых других компонент и подсистем.
Масштабировать скорость создания и обновления индекса можно безболезненным увеличением серверов создания порций индекса IS, каждый из которых будет отвечать за свою группу CA. Есть некоторые проблемы объединения большого объема исходных индексных данных на различных IS, однако они решаемы.
Масштабировать увеличивающийся суммарный объем индекса в пределах одного поискового кластера можно увеличением количества процессоров поиска. В пределе, данные по каждому отдельному поисковому термину могут находиться на собственном поисковом процессоре.
Архивные сервера AS свободно добавляются в систему по мере накопления новых данных, при этом конфигурационно определяется сфера ответственности каждого из них в виде интервалов ID-документов.
Увеличивающиеся во времени поисковые нагрузки можно гасить путем увеличения количества кластеров индекса и, соответственно, количеством QP. В целом, ориентация на недорогие, но надежные аппаратные платформы позволяет создать и поддерживать систему умеренной стоимости.
Масштабируемость по функциональности различных языков легко достигается включением новых морфологических словарей в систему. Инструменты для создания таких словарей разработаны нами в составе Multilingual Morphology Module (MMM/1.0).
Масштабируемость по обработке новых видов данных осуществляется с помощью подключения новых фильтров - преобразователей форматов.
5. Контроль работоспособности и статистика.
Мы видим, что предложенная модель содержит массу взаимосвязанных компонент. Работоспособность системы в целом зависит от правильного выполнения своих функций каждого "винтика" системы. "Ни что не вечно под луной", оборудование имеет неприятное свойство выходить из строя, причем, обычно, в самое неподходящее для этого время.Как было указано в начале, потеря работоспособности одного из агентов накопления CA не может привести к фатальным последствиям работы всего комплекса накопления. Это же замечание можно с уверенностью трансформировать на оптимизаторы запросов QP и процессоры поиска SP. Их количество в системе достаточно для того, чтобы в экстренных ситуациях обслужить поисковые запросы до тех пор, пока "испорченный" элемент будет заменен на новый. Отметим также, что каждый SP в любой момент может взять на себя функции резерва смежного процессора поиска. Данные смежного SP копируются на него в фоновом режиме с низким приоритетом непрерывно, не мешая другим компонентам работать.
Сервер создания новой порции индекса IS осуществляет свою работу периодически. В случае выхода его из строя, обновление индекса в системе может быть приостановлено на период замены (обычно не превышающий двух суток) и никто подобной приостановки не сможет заметить. Сохранение результатов на Cache-сервере также не имеет принципиального для жизнедеятельности значения, хотя и увеличит нагрузку на остальные компоненты системы.
Самыми важными узлами механизма являются центральный диспетчер и архивные сервера. Именно поэтому архивные сервера выполняются на надежных RAID-5 массивах, способных восстанавливать частично утерянные данные. Данные центрального диспетчера следует периодически сохранять на внешних носителях, например, магнитных лентах. Реально по данным архивных серверов можно восстановить данные для любой жизненно важной компоненты системы, включая диспетчер.
В целом, если мы имеем механизм взаимодействия различных подсистем в виде SSTP-протокола, то этим же механизмом можно воспользоваться и для контроля работоспособности отдельных его элементов. Для этих целей в системе предусмотрен сервер контроля работоспособности Monitoring Server (MS), который периодически опрашивает жизненно важные узлы и бьет тревогу в случае отсутствия положительного ответа от них.
Нетрудно понять, что в рамках предложенной модели явно прослеживаются и центры кристаллизации статистических данных. Такими центрами являются центральный диспетчер DS, архивный сервер AS, формирователь индекса IS и балансировщик нагрузки LB. Пользуясь статистическими данными этих серверов, можно производить массу разнообразных исследования, связанных как с содержанием документов коллекции, так и с поведением пользователей поисковой системы.
6. Заключение.
Подведем черту. Прототип поисковой системы описан и реализован. Оценим, что реально мы проделали. Из общей мировой коллекции документов мы "выкусили" около 100 миллионов документов (по нашим оценкам, это составляет 1-1.5%) и построили по этой коллекции распределенный поиск. Такую коллекцию документов и поиск по ней назовем обобщающим термином SET. Что мешает нам повторить данный опыт 99 раз на оставшихся документах и сделать еще 99 сетов? Необходимо лишь правильно распределить сферу ответственности каждого сета.Организуя поиск по всей коллекции документов, необходимо просто объединять данные поиска из каждого сета (мы подразумеваем при этом, что законы вычисления релевантности в каждом сете одинаковые).
Однако не все так просто. Одной из характеристик документа мы считаем PageRank. Эта характеристика документа высчитывалась нами только в пределах одного сета. На практике документы очень часто содержат ссылки на документы, которые входят в другой сет. Это означает, что данные ссылки мы обязаны сохранить где-то в стороне для их последующей обработки и построения результирующей матрицы ссылок документов друг на друга. Очевидно, что с позиции общей мировой коллекции идентификатор документа будет комплексным и будет состоять из идентификатора сета и идентификатора документа внутри сета.
Процесс формирования результатов такого слияния следует спроектировать в будущем. Нам примерно понятно, как это следует реализовать, однако пока такой задачи мы перед собой не ставили.
В данной работе рассмотрены лишь общие принципы современной поисковой системы Web-ресурсов для того, чтобы дать представление о том, насколько она сложна. Чем дальше я размышляю о перспективах совершенствования различных компонент современной поисковой системы и о разработках принципиально новых компонент такой системы, тем отчетливее для меня становится тот факт, что построение подобной системы должно иметь распределенных характер и на уровне владельцев ресурсов поиска. Как бы велики ни были ресурсы отдельно взятой компании, темпы роста количества информации всегда будут опережать возможности такой компании. Осознание этого факта другими участниками сетевой деятельности неизменно должно привести к интеграции усилий в этом направлении. Мы готовы уже сейчас рассматривать новые модели поиска в сети с учетом всех современных разработок. Если сетевой мир признает подобные разработки основополагающими, то за создание и поддержку такого распределенного сервиса оно будет готово платить. Вспомним ситуацию с Domain Name System - теперь никого не удивляет, что регистрация доменов (читай - ресурсов сети) является платной услугой. Будущее - именно за такими распределенными поисковыми системами.
Благодарности.
Я выражаю глубокую благодарность Евгению Родичеву, принимавшему и принимающему самое активное участие в обсуждении различных компонент данной работы. Многие высказанные им предположения и идеи были в дальнейшем взяты на вооружение, развиты и модернизированы. Хочу также выразить благодарность Федору Сигаеву, который на практике осуществлял воплощение важной компоненты системы QP, его замечания и предложения учитывались в процессе видоизменения взаимодействий различных компонент "Turtle". Сергей Аюков внес свой вклад в общую систему, проектируя систему локального отчуждаемого поиска, который мы распространяем в рамках популяризации нашей поисковой системы. Его описание приведено в документации на поставляемое нами программное обеспечение.
|
|
 | ||
|
|
|
| Черепаший Ранк. Реклама на Turtle Логотипы Правовая информация Конфиденциальность Контакты |