| Добавить Архитектура Запросы сейчас Цифры и факты FAQ Кнопка поиска Сделать стартовой |
3.7. Ранжирование результатов.
Предположим, что функции поиска мы полностью реализовали и теперь нам требуется расставить найденные документы в правильном порядке; первые документы, по мнению поисковой системы, должны наиболее точно соответствовать поисковому запросу. Функция такого ранжирования всегда является базовой для любой поисковой системы. По качеству ранжирования пользователи судят в целом о качестве поисковой системы. Существует множество описанных методов, суть которых сводится к одному - каждому найденному по запросу документу следует поставить в соответствие некое характеристическое число и отсортировать выборку по убыванию этого весового коэффициента.В базовой модели поиска системой "Turtle" заложен принцип использования различных параметров, которые оказывают влияние на результаты ранжирования. В общем случае формулу для вычисления характеристики документа в результатах поиска можно представить так:
RL(x) = K1*PP(x) + K2*PT(x) + K3*PR(x) + K4*CO(x)+...
Заметим, что в конце формулы мы поставили многоточие. Этим мы хотим обозначить тот факт, что при разработке нового метода ранжирования мы будем способны ввести такой новый фактор в наши вычисления результирующей функции ранжирования.
- где
- RL - результирующая релевантность документа х;
- PP - предвычисленная характеристика частотности термина в документе х;
- PT - предвычисленная характеристика местоположения термина в различных полях HTML-тэгов документа (если документ является HTML);
- PR - PageRank данного документа, согласно определению. Эта величина не зависит от содержания запроса;
- CO - функция, учитывающая координатное положение внутри документа терминов поискового запроса;
- K1-K4 - нормировочные коэффициенты для соответствующих функций.
Так, например, мы до конца для себя не решили, стоит ли учитывать слова, находящиеся в поле ссылки, для ссылаемого документа. С одной стороны, автор документа, содержащего такую ссылку, явно ее назвал. Слова, обрамляющие данную ссылку, могут быть привязаны к тому документу, на который ссылается данный текст. Однако на практике часто бывает, что документ ссылается на головную страницу новостного ресурса, который более не содержит данной рубрики в себе. Кроме того, учитывая слова ссылок, мы добавим в систему некий фактор субъективизма человека, который написал исходный документ, и перенесем этот фактор на ссылаемый документ. Поясню свою мысль на простом примере. Предположим, что в нашей гипотетической базе данных имеется всего три документа, два из которых ссылаются на третий. В первом документе ссылку на третий документ обрамляют слова: "прекрасный документ". Второй документ ссылается на третий словами: "безобразный документ". По каким ключевым словам мы найдем третий документ в данной системе и удовлетворят ли нас результаты найденного? Пример, конечно, надуман, но не так далек от реальной жизни. Так, например, одна известная поисковая система по Web-ресурсам, использующая механизм ссылок слов других документов, на запрос, состоящий из выражений ругательного характера, первой же ссылкой результатов поиска выдавала название крупнейшей компании по производству программного обеспечения. Хорошо это или плохо, судить пользователям поисковой системы. В любом случае, технически проделать это в рамках представленного прототипа довольно просто. Главное, постараться правильно формализовать степень влияния таких слов.
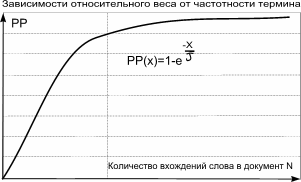
Несмотря на то, что компоненты формулы входят в нее как линейная комбинация с соответствующими коэффициентами влияния, каждая из этих функций не является линейной. Так, например, функция, учитывающая частотность термина в пределах документа имеет вид:
Как видно из приведенного графика, результирующая функция ведет себя линейно до некоторой точки в зависимости от количества вхождений слова. После прохождения этой точки увеличение количества терминов не вносит существенных изменений в значение результата. Это можно рассматривать как один из способов борьбы с искусственным завышением функции релевантности хозяевами ресурсов. Значение коэффициента T может изменяться в зависимости как от размеров коллекции, так и от смыслового поля HTML документа (или любого другого типа документа, содержащего в себе структурные части текста). На практике мы используем множество таких методов и не станем приводить здесь их описание. Одной из компонент результирующей релевантности является очень модный сейчас термин "PageRank" в его классическом определении, которое я не стану приводить здесь. Некоторые полагают, что использование PageRank поисковой системой Google является решающим фактором в соревновании качества поисковых машин. Конечно, использование ранка документов является важным элементом ранжирования, однако назвать его решающим я бы не рискнул. На мой взгляд, это всего лишь одна из нескольких составляющих ранжирования, ни больше, ни меньше.
Несколько слов для непосвященных. Метод вычисления PageRank основан на построении графа, узлами которого являются идентификаторы документов коллекции, а ребрами являются ссылки документов друг на друга. После построения такого графа производится вычисление весов узлов в зависимости от количества входящих и исходящих ребер, согласно определению. Здравый смысл подсказывает, что чем больше документов ссылается на какой либо конкретный документ, тем больше его значимость для коллекции в целом. Беда заключается в том, что для вычисления PageRank результирующий граф должен быть полностью связанным, чего в реальной жизни, увы, не происходит. Существуют методы и алгоритмы для выделения сильно связанных компонент таких графов. Их может оказаться несколько, и манипуляции с такими компонентами являются ноу-хау каждой из поисковых систем. Переоценка важности фактора PageRank может привести к различным казусным ситуациям. Известны случаи, когда владелец сайта-форума помещал на каждой его странице ссылку на сайт друга, обрамленную одними и теми же словами. Форум имел достаточно оживленную дискуссию и сайт друга владельца неизменно поднимался в результатах поиска поисковой машины, использующей фактор PageRank как решающий при вычислении релевантности.
Однако, вернемся к результирующей формуле релевантности. Особо обращаю внимание на то, что правильное определение нормировочных коэффициентов для каждой из составляющих результирующего значения ранжирования на практике является настоящим искусством. Эти коэффициенты учитывают как объективные факторы влияния термина на документ, так и субъективные. По этой причине, хранение весовых характеристик разного физического смысла следует осуществлять раздельно и "смешивать" их в определенной пропорции только на завершающем этапе поиска перед сортировкой результатов.
Кстати, о сортировке. Алгоритмы сортировки современной поисковой машины могут (и должны быть) разными в зависимости от того, какое количество результатов было найдено и какое количество результатов реально требуется. Предположим, что в результате выполнения поискового запроса был найден 1 миллион ссылок. Нет смысла сортировать весь этот набор данных. В самом деле, какая вам разница, какой документ будет на 500001 позиции, а какой на 500002, если вы собираетесь просмотреть только первые 500. Мы проектируем поисковую машину для живых людей. Исходя из этого, достаточно правильно отобрать требуемое количество наилучших результатов, а уже их потом отсортировать. Подобные механизмы сортировок были разработаны в нашей компании Федором Сигаевым. Они с успехом находят применение и в других программных продуктах, например, используются в СУБД PostgreSQL http://www.postgresql.org/. Универсализм в подходах к решению разноплановых задач хорош с точки зрения компактности кода, но никак не с точки зрения быстродействия.
|
|
 | ||
|
|
|
| Черепаший Ранк. Реклама на Turtle Логотипы Правовая информация Конфиденциальность Контакты |