| Добавить Архитектура Запросы сейчас Цифры и факты FAQ Кнопка поиска Сделать стартовой |
3.5. Базовая функция поиска документов.
Подойдем к вопросу функционирования поисковой системы Web-ресурсов с противоположной стороны, предположив, что какая-то составляющая комплекса умеет создавать из данных, накопленных CA, пригодный для поиска индекс. Причем умеет это делать именно в таком виде, какой нам потребуется для оптимального поиска. Рассмотрим возможные способы его хранения, а также то, как механизмы поиска будут связаны с выбранным способом хранения индекса. В качестве элементов прикидки будем использовать все те же оценочные характеристики русскоязычного сегмента сети Интернет.Анализ различных существующих реализаций полнотекстового поиска (а именно таковой мы проектируем) показывает, что в зависимости от полноты сохраняемой информации, методов хранения, дополнительных данных хранения и т.п. результирующий суммарный объем индекса может составлять от 15 до 200 % от суммарного количества исходных данных или, в нашем случае, от суммарной длины документов сканирования. Предположим достаточно оптимистично, что мы выбрали такую модель индекса, которая обеспечивает его суммарный размер на уровне 30% от общего размера документов. В пересчете на рассматриваемый нами российский сегмент сети Интернет предполагаемый размер индекса составит 70млн.*25КБ*30/100, или чуть более половины терабайта.
Вот с таким объемом информации нам придется быстро работать, при условии, что мы строим поисковую машину для России. Страшно подумать, что же будет в масштабах всего мира? Очевидно по многим соображениям, что такой индекс следует "размазать" по нескольким серверам по соображениям физической вместимости, быстродействия, способности к реплицированию, возможности параллельной обработки и пр. Чтобы понять, как индекс вообще можно разделить по нескольким серверам, сначала опишем информацию, которую должен содержать в себе этот индекс.
Ключом для поиска всегда является поисковый термин, или лексема. Индекс должен содержать информацию о номерах документов (ID), в которых данный поисковый термин встретился. Кроме того, индекс должен содержать координатную информацию слова в каждом конкретном документе.
Кстати говоря, когда мы разрабатывали в 1996 году поисковую систему Рамблер, то в силу ограниченности материальных ресурсов индекс не содержал координатной информации. Тем не менее, поисковая система Рамблер долго показывала вполне сносные результаты и без него. Теперь, конечно, там все не так, однако полагаю, что программное обеспечение Рамблер нельзя смасштабировать до уровня мировой поисковой системы, оно просто на это не рассчитано. Впрочем, я могу ошибаться. Современные российские поисковые систе мы не очень охотно описывают свои "внутренности".
Неплохо было бы также наделить индекс некоей качественной информацией об уровне значимости данного поискового термина в рамках данного документа. Частота употребления термина, его положение в тексте, близость смежных терминов, способы выделения термина, цвет букв шрифта, если документ является HTML, и т.д. оказывают влияние на этот качественный показатель. Нельзя также забывать о мерах предосторожности против "находчивых" владельцев ресурсов, старающихся любым способом заставить поисковый движок показывать его документы первыми, даже в случае, если содержание текста документа далеко от соответствия данному поисковому термину. Также хотелось бы в индексе учесть и саму значимость документа с точки зрения всей коллекции документов: как часто цитируется данный документ и насколько авторитетны источники, которые на него ссылаются. Можно придумать еще массу параметров, содержащихся в индексе, однако вспомним о размере и пока ограничимся этим. Более подробно строение индекса и механизмы ранжирования будут описаны в дальнейшем.
В пределе простой индекс может содержать только сами слова и номера документов, в которых они содержатся. Такой индекс можно разбить по нескольким серверам только двумя способами:
И тот, и другой способ имеют право на жизнь. У каждого из них - свои достоинства и недостатки. Не вдаваясь в подробности анализа, отмечу, что мы выбрали первый способ разбиения индекса. Каждый из равноправных компьютеров процессоров поиска содержит информацию о терминах определенного диапазона. Вопрос лишь в том, как именно распределены эти диапазоны.
- Разбить поисковые термины на интервалы (скажем, по первым буквам).
- Разбить индекс так, чтобы в пределах одного сервера содержались все термины, относящиеся к определенному диапазону номеров (ID) документов.
Для правильного разделения индекса по первой модели следует осознавать, что, с одной стороны, индекс должен быть разбит примерно на равные части по размеру, чтобы уравновесить конфигурацию типового компьютера для поиска. С другой стороны, количество суммарных обращений к каждому из серверов для хорошей нагрузочной способности должно быть примерно равным, чтобы уравновесить в целом поисковую систему. Нельзя допускать ситуации, в которой один из поисковых серверов постоянно загружен, а другой простаивает.
Первый параметр разбиения индекса определяется частотностью слов в документах, второй - частотностью слов в запросах пользователей. К счастью, мы владеем соответствующими данными и имеем оценочные характеристики обоих параметров в условиях российского Интернета. Если же мы соберемся перестроиться на систему мирового масштаба, то, наряду с увеличением процессоров поиска нам также потребуется выбрать иные интервалы разбиения индекса, исходя из реалий жизни. Однако это никаким образом не повлияет на программное обеспечение поиска.
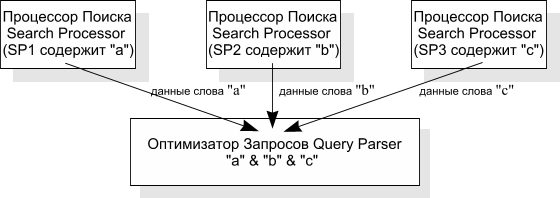
Попробуем представить примерную схему поисковой работы с таким индексом. Предположим, что нам требуется найти документы, содержащие слова "a", "b" и "c" одновременно. Предположим также, что индекс слова "a" находится на поисковом процессоре SP1, индекс слова "b" - на SP2, "c" - на SP3. Первоначальная схема поиска может выглядеть примерно так:
В этом случае все данные о каждом поисковом термине "a", "b" и "c" передаются на внешнюю программу, на которой производится выбор ID-документов, которые удовлетворяют всем условиям.
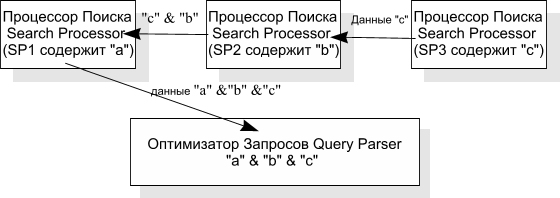
Эту же работу можно выполнить иным способом, например, так:
Данный пример отличается от предыдущего тем, что по сети мы передаем значительно меньше данных, т.к. от SP2 к SP1 уже следует пачка идентификаторов ID, удовлетворяющая условиям "c" И "b" в одном документе. От SP1 к разборщику запросов "едет" чистый результат логического пересечения всех ID. Однако, для реализации этого механизма нам необходимо "научить" взаимодействовать SP друг с другом в рамках разработанного нами протокола SSTP. Ну и кроме того, SP должен являеться не просто хранителем индекса, но и обязан "уметь" осуществлять требуемые логические операции. Сейчас в арсенале SP реализовано 8 различных операций с данными по поисковым терминам, среди которых есть экзотические типа "исключающее ИЛИ".
Теперь представим себе на минуту, что размер индекса слова "c" значительно превышает размер индекса слов "b" и "a". В таком случае очевидно, что выбранная схема поиска не является оптимальной. Оптимальней было бы получать результаты от SP3, т.к. при обратной схеме потоков данных о словах нам бы пришлось передавать по сети от одного поискового процессора к другому меньше данных. Нетрудно понять, что в случае логического поиска документов, содержащих все поисковые термины, выгодно выстраивать именно цепь взаимодействий, т.к. каждый промежуточный результат будет по своему объему меньше, чем предыдущий. При поиске документов, содержащих любой термин, выгоднее собрать информацию по каждому из них в общей точке и там произвести объединение, т.к. после каждой элементарной операции объединения количество результатов будет превышать исходное.
В общем случае поисковый запрос может иметь весьма сложную структуру с учетом морфологических форм и языка запроса и выполняется различными способами. Логические схемы выполнения сложного поискового запроса могут быть представлены сложными деревьями с закольцованными взаимодействиями. Напрашивается вывод, что кто-то должен, проанализировав исходные данные, для каждого конкретного поиска выбрать наиболее оптимальный по времени способ выполнения. Эти задачи мы возлагаем на разборщик запросов Query Parser (QP). Из всех возможных вариантов выполнения данного запроса он выбирает самую быструю схему и согласно этой схеме составляет программу работы всего поискового комплекса для выполнения задачи.
Для того чтобы различные SP могли взаимодействовать друг с другом, в рамках протокола был разработан язык выполнения поисковых программ Search System Assembly Language, который содержит набор директив каждому конкретному SP. Программа, написанная на этом языке, формируется на QP с учетом оптимизации ее выполнения по времени и передается на выбранный SP. Это настоящий специализированный язык программирования, содержащий в себе два десятка операторов, включая операторы условного перехода. С технической документацией на SSAL можно познакомиться здесь.
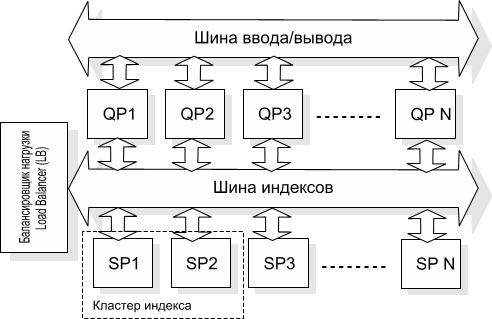
Если в рамках поисковой системы возникает ситуация, когда набор SP, содержащий полный индекс базы (мы называем его кластером индекса), не успевает обработать все входящие запросы, то это означает, что нам пора ввести еще один кластер, содержащий полный индекс, вернее, точную его копию. Он может архитектурно отличаться от уже существующего (например, быть выполнен на платформе DEC, а не Intel, но лучше все же придерживаться одной архитектурной линии. Мы выбрали для себя Intel-платформу, наиболее точно для нас отражающую соответствие цена/качество).
Нетрудно заметить, что при обработке одного запроса не всегда в работе принимает участие весь поисковый кластер. Запрос из одного слова всегда обрабатывается только одним процессором поиска при выбранном нами способе разбиения индекса, все остальные в данный момент времени являются свободными. Отсюда можно сделать вывод, что архитектура фиксированных или статических кластеров индекса не является самой оптимальной.
Введем понятие динамического кластера индекса. Динамическим кластером индекса будем называть совокупность свободных (или наименее занятых) в данный момент процессоров поиска SP, формируемых внешней программой для выполнения конкретного поискового запроса. Очевидно, что сформировать такой динамический кластер может программа, которая имеет представление о состоянии каждого процессора поиска системы. Мы называем такой сервер балансировщиком нагрузки Load Balancer (LB). Этот сервер способен держать в памяти текущие и планируемые состояния каждого из SP и по запросу оптимизатора QP выдавать динамическую конфигурацию кластера индекса для выполнения поискового запроса.
Итак, как видим, что для поддержания базовой функции поиска в архитектуре нашей поисковой системы нам необходимы еще три типа серверов. Это оптимизатор запросов Query Parser, поисковый процессор Search Processor и балансировщик нагрузки Load Balancer. Результирующая схема поисковой машины с полюса поиска может выглядеть пока так:
|
|
 | ||
|
|
|
| Черепаший Ранк. Реклама на Turtle Логотипы Правовая информация Конфиденциальность Контакты |