| Добавить Архитектура Запросы сейчас Цифры и факты FAQ Кнопка поиска Сделать стартовой |
3.1. Базовая функция извлечения данных.
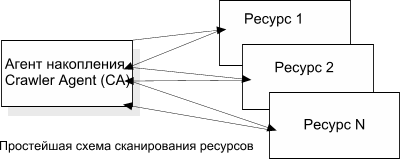
Представим себе, что в нашей системе есть только один компьютер, который занимается сканированием Web-ресурсов, последовательно осуществляя следующие действия:
- Выяснение соответствия логического имени сервера ресурса и его реального Интернет IP-адреса посредством системы Domain Name System (DNS).
- Установление соединения с удаленным сервером.
- Передача запроса серверу посредством Hypertext Transfer Protocol (HTTP).
- Получение от внешнего сервера результатов запроса.
- Анализ ответа и извлечение новых объектов для сканирования (URL).
Предположим, что средняя скорость среды при взаимодействии с внешним сервером составляет примерно 50 КБ/сек (что можно считать весьма реальной ситуацией, т.к. множество ресурсов до сих пор так и не обладает достаточно скоростными каналами подключения). Предположим, что средний размер документа сети составляет 25 КБ, что также близко к реальности. Попытаемся оценить производительность нашей примитивной системы накопления, исходя из таблицы средних времен указанных операций:
DNS 0.05 Соединение с сервером 0.05 Передача запроса 0.05 Прием запроса 0.5 Анализ 0.05 Итого: 0.7 Таким образом, наша система тратит на один документ в среднем 0.7 секунды. Это означает, что за сутки она сможет "обработать" примерно 120 тысяч документов. Вспомним, что российский Интернет по численности документов мы оценивали примерно в 70 млн. Итак, сканирование только российской части Интернета нашей гипотетической системой составит полтора года. Результат не удовлетворителен с любой точки зрения.
Попробуем понять, что можно улучшить в нашей системе. Как видно из таблицы, большую часть времени система простаивает (с точки зрения процессора), она занята приемом данных документа на 70%. Очевидно, что если в любой момент времени систему накопления обеспечить данными для обработки, то работа ее станет куда эффективней. Для того, чтобы данные всегда присутствовали для обработки на накопителе (мы называем его Crawler Agent), достаточно организовать передачу и прием запросов в несколько потоков одновременно, при окончании данных в одном из потоков программа немедленно приступает к обработке данных, полученных из него.
При внедрении подобного метода производительность одного Crawler Agent (CA) может составить примерно 500 тыс. документов в сутки при условии, что мы не модернизировали компьютер CA, в конфигурацию которого входит 64MB RAM, 600Mhz Intel Pentium процессор и недорогой IDE HDD. Время сканирования российского Интернета в таком случае составит уже 140 дней, что существенно лучше, но продолжает быть не удовлетворительным для выполнения поставленной задачи. Пока мы только пришли к выводу, что CA по своей природе должен быть многопоточным.
Теперь попробуем увеличить количество CA с одного до десяти. Время сканирования российской части Интернета составит в этом случае 14 дней, что вполне удовлетворительно для инерционных поисковых систем.
Однако что делать в случае, когда какой-либо документ по каким-либо причинам не содержит ссылок на новые объекты сканирования? Куда помещать результаты сканирования? Как узнать, какую работу уже проделал соседний CA, чтобы избежать повторений? Как уменьшить накладные расходы работы с DNS? Как идентифицировать объект сканирования? Как узнать, изменился ли этот объект с момента последнего сканирования? Возникает масса вопросов.
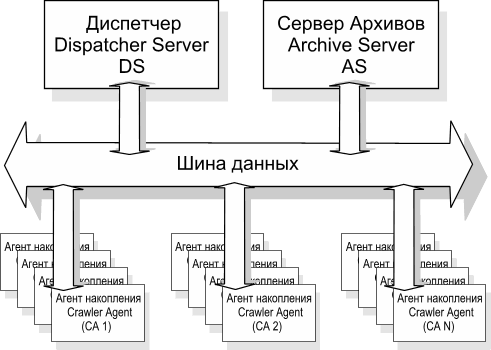
Мы приходим к выводу, что работа множества CA требует координации. Таким координирующим центром может и должен являться центральный диспетчер (Dispatcher Server), который сам непосредственно не занимается сканированием документов, а поддерживает очереди для CA и по их первому требованию может выдать описание нового объекта для сканирования. Диспетчер также занимается отслеживанием результатов сканирования, передаваемых ему агентами, помещением вновь найденных объектов для сканирования в соответствующие очереди с присвоением им уникальных идентификаторов. Он помечает несуществующие документы с целью предотвращения повторного сканирования, может формировать приоритеты в очереди документов и пр.
Рассматривая далее процесс жизнедеятельности CA, законно предположить, что он существует не только для того, чтобы сканировать документы и передавать вновь появившиеся ссылки. С полученными по сети документами CA обязан проделать некоторые подготовительные действия для получения исходных данных для поиска. Таковыми действиями являются определение языка документа, определение кодировки документа, возможно определение темы документа, если мы наделим CA соответствующими знаниями. Документ должен быть разобран на лексемы с учетом знаков препинания и пр., а результаты где-то отложены для их дальнейшего использования. При этом неплохо было бы иметь некое общее и достаточно вместительное хранилище, куда можно было бы положить оригиналы документов в том же виде, в каком их получил CA. Возможно, в дальнейшем мы придумаем новые методы обработки полученных документов, поэтому сохранение оригиналов является также необходимым условием.
Очевидно, что для подобных задач не подходит компьютер агента накопления CA в силу своей ограниченности. На практике стоимость аппаратного обеспечения CA равна примерно $500 (типовая конфигурация описана выше), половину этой суммы составляет стоимость индустриального корпуса в стойку. Оптимизация по стоимости CA важна с той точки зрения, что их количество в системе будет расти пропорционально суммарному количеству сканируемых документов сегментов сети из расчета 500 тысяч документов в сутки на один компьютер CA. В то же время, выход из строя одного из CA не должен вносить никакого существенного влияния в целом на процесс накопления. Исходя из этого, делаем предположение, что для хранения объектов накопления следует обзавестись выделенным сервером или несколькими серверами, которые по вместительности будут значительно превышать CA. Мы называем такие сервера архивными (Archive Server). При условии, что данные на таком сервере могут храниться в компрессированном виде, нетрудно посчитать, что одного сервера с массивом RAID объемом в 500GB должно хватать примерно на коллекцию в 50 млн. документов (на практике возможно меньше, во всяком случае, мы не ошибемся сильно в порядке). Количество архивных серверов напрямую зависит от количества сканируемых документов и с течением времени будет медленно расти. Сферу ответственности архивных серверов можно определить конфигурационно в виде интервалов идентификаторов документов, за которые данный архивный сервер несет ответственность. Такая конфигурация может быть централизовано сохранена на диспетчере и выдана любому участнику поисковой системы по его запросу при условии, что запрос прошел соответствующую авторизацию:
Archiver-001 1-20000000 Archiver-002 20000001-40000000 Попробуем отобразить, во что превращается наша система накопления. С учетом всего сказанного выше схема может иметь вид:
|
|
 | ||
|
|
|
| Черепаший Ранк. Реклама на Turtle Логотипы Правовая информация Конфиденциальность Контакты |